Mean
In statistics, mean has two related meanings:
- the arithmetic mean (and is distinguished from the geometric mean or harmonic mean).
- the expected value of a random variable, which is also called the population mean.
There are other statistical measures that should not be confused with averages - including 'median' and 'mode'. Other simple statistical analyses use measures of spread, such as range, interquartile range, or standard deviation. For a real-valued random variable X, the mean is the expectation of X. Note that not every probability distribution has a defined mean (or variance); see the Cauchy distribution for an example.
For a data set, the mean is the sum of the values divided by the number of values. The mean of a set of numbers x1, x2, ..., xn is typically denoted by 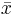 , pronounced "x bar". This mean is a type of arithmetic mean. If the data set were based on a series of observations obtained by sampling a statistical population, this mean is termed the "sample mean" () to distinguish it from the "population mean" (
, pronounced "x bar". This mean is a type of arithmetic mean. If the data set were based on a series of observations obtained by sampling a statistical population, this mean is termed the "sample mean" () to distinguish it from the "population mean" (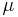 or x). The mean is often quoted along with the standard deviation: the mean describes the central location of the data, and the standard deviation describes the spread. An alternative measure of dispersion is the mean deviation, equivalent to the average absolute deviation from the mean. It is less sensitive to outliers, but less mathematically tractable.
or x). The mean is often quoted along with the standard deviation: the mean describes the central location of the data, and the standard deviation describes the spread. An alternative measure of dispersion is the mean deviation, equivalent to the average absolute deviation from the mean. It is less sensitive to outliers, but less mathematically tractable.
If a series of observations is sampled from a larger population (measuring the heights of a sample of adults drawn from the entire world population, for example), or from a probability distribution which gives the probabilities of each possible result, then the larger population or probability distribution can be used to construct a "population mean", which is also the expected value for a sample drawn from this population or probability distribution. For a finite population, this would simply be the arithmetic mean of the given property for every member of the population. For a probability distribution, this would be a sum or integral over every possible value weighted by the probability of that value. It is a universal convention to represent the population mean by the symbol .[1] In the case of a discrete probability distribution, the mean of a discrete random variable x is given by taking the product of each possible value of x and its probability P(x), and then adding all these products together, giving 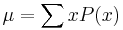 .[2]
.[2]
The sample mean may differ from the population mean, especially for small samples, but the law of large numbers dictates that the larger the size of the sample, the more likely it is that the sample mean will be close to the population mean.[3]
As well as statistics, means are often used in geometry and analysis; a wide range of means have been developed for these purposes, which are not much used in statistics. These are listed below.
Examples of means
Arithmetic mean (AM)
The arithmetic mean is the "standard" average, often simply called the "mean".
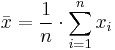
The mean may often be confused with the median, mode or range. The mean is the arithmetic average of a set of values, or distribution; however, for skewed distributions, the mean is not necessarily the same as the middle value (median), or the most likely (mode). For example, mean income is skewed upwards by a small number of people with very large incomes, so that the majority have an income lower than the mean. By contrast, the median income is the level at which half the population is below and half is above. The mode income is the most likely income, and favors the larger number of people with lower incomes. The median or mode are often more intuitive measures of such data.
Nevertheless, many skewed distributions are best described by their mean – such as the exponential and Poisson distributions.
For example, the arithmetic mean of six values: 34, 27, 45, 55, 22, 34 is
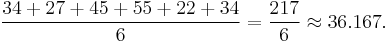
Geometric mean (GM)
The geometric mean is an average that is useful for sets of positive numbers that are interpreted according to their product and not their sum (as is the case with the arithmetic mean) e.g. rates of growth.
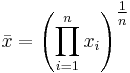
For example, the geometric mean of six values: 34, 27, 45, 55, 22, 34 is:
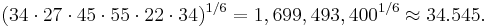
Harmonic mean (HM)
The harmonic mean is an average which is useful for sets of numbers which are defined in relation to some unit, for example speed (distance per unit of time).
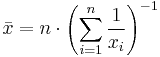
For example, the harmonic mean of the six values: 34, 27, 45, 55, 22, and 34 is
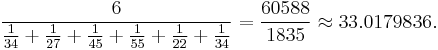
Relationship between AM, GM, and HM
AM, GM, and HM satisfy these inequalities:
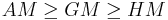
Equality holds only when all the elements of the given sample are equal.
Generalized means
Power mean
The generalized mean, also known as the power mean or Hölder mean, is an abstraction of the quadratic, arithmetic, geometric and harmonic means. It is defined for a set of n positive numbers xi by
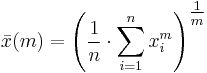
By choosing the appropriate value for the parameter m we get all means:
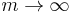 |
maximum |
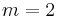 |
quadratic mean |
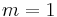 |
arithmetic mean |
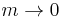 |
geometric mean |
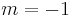 |
harmonic mean |
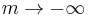 |
minimum |
ƒ-mean
This can be generalized further as the generalized f-mean
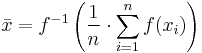
and again a suitable choice of an invertible ƒ will give
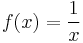 |
harmonic mean, |
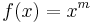 |
power mean, |
 |
geometric mean. |
Weighted arithmetic mean
The weighted arithmetic mean is used, if one wants to combine average values from samples of the same population with different sample sizes:
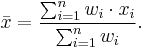
The weights 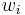 represent the bounds of the partial sample. In other applications they represent a measure for the reliability of the influence upon the mean by respective values.
represent the bounds of the partial sample. In other applications they represent a measure for the reliability of the influence upon the mean by respective values.
Truncated mean
Sometimes a set of numbers might contain outliers, i.e. a datum which is much lower or much higher than the others. Often, outliers are erroneous data caused by artifacts. In this case one can use a truncated mean. It involves discarding given parts of the data at the top or the bottom end, typically an equal amount at each end, and then taking the arithmetic mean of the remaining data. The number of values removed is indicated as a percentage of total number of values.
Interquartile mean
The interquartile mean is a specific example of a truncated mean. It is simply the arithmetic mean after removing the lowest and the highest quarter of values.
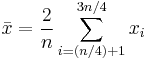
assuming the values have been ordered, so is simply a specific example of a weighted mean for a specific set of weights.
Mean of a function
In calculus, and especially multivariable calculus, the mean of a function is loosely defined as the average value of the function over its domain. In one variable, the mean of a function f(x) over the interval (a,b) is defined by
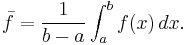
Recall that a defining property of the average value 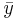 of finitely many numbers
of finitely many numbers 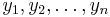 is that
is that 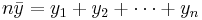 . In other words, is the constant value which when added to itself
. In other words, is the constant value which when added to itself  times equals the result of adding the terms of
times equals the result of adding the terms of 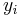 . By analogy, a defining property of the average value
. By analogy, a defining property of the average value 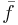 of a function over the interval
of a function over the interval ![[a,b]](/2012-wikipedia_en_all_nopic_01_2012/I/2c3d331bc98b44e71cb2aae9edadca7e.png) is that
is that
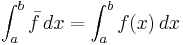
In other words, is the constant value which when integrated over equals the result of integrating 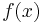 over . But by the second fundamental theorem of calculus, the integral of a constant is just
over . But by the second fundamental theorem of calculus, the integral of a constant is just
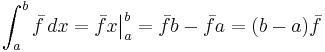
See also the first mean value theorem for integration, which guarantees that if 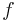 is continuous then there exists a point
is continuous then there exists a point 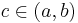 such that
such that
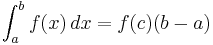
The point 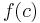 is called the mean value of on . So we write
is called the mean value of on . So we write 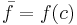 and rearrange the preceding equation to get the above definition.
and rearrange the preceding equation to get the above definition.
In several variables, the mean over a relatively compact domain U in a Euclidean space is defined by
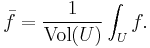
This generalizes the arithmetic mean. On the other hand, it is also possible to generalize the geometric mean to functions by defining the geometric mean of f to be
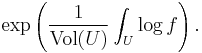
More generally, in measure theory and probability theory either sort of mean plays an important role. In this context, Jensen's inequality places sharp estimates on the relationship between these two different notions of the mean of a function.
There is also a harmonic average of functions and a quadratic average (or root mean square) of functions.
Mean of a probability distribution
See expected value.
Mean of angles
Most of the usual means fail on circular quantities, like angles, daytimes, fractional parts of real numbers. For those quantities you need a mean of circular quantities.
Fréchet mean
The Fréchet mean gives a manner for determining the "center" of a mass distribution on a surface or, more generally, Riemannian manifold. Unlike many other means, the Fréchet mean is defined on a space whose elements cannot necessarily be added together or multiplied by scalars. It is sometimes also known as the Karcher mean (named after Hermann Karcher).
Other means
- Arithmetic-geometric mean
- Arithmetic-harmonic mean
- Cesàro mean
- Chisini mean
- Contraharmonic mean
- Elementary symmetric mean
- Geometric-harmonic mean
- Heinz mean
- Heronian mean
- Identric mean
- Lehmer mean
- Logarithmic mean
- Median
- Moving average
- Root mean square
- Rényi's entropy (a generalized f-mean)
- Stolarsky mean
- Weighted geometric mean
- Weighted harmonic mean
Properties
All means share some properties and additional properties are shared by the most common means. Some of these properties are collected here.
Weighted mean
A weighted mean M is a function which maps tuples of positive numbers to a positive number
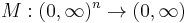
such that the following properties hold:
- "Fixed point": M(1,1,...,1) = 1
- Homogeneity: M(λ x1, ..., λ xn) = λ M(x1, ..., xn) for all λ and xi. In vector notation: M(λ x) = λ Mx for all n-vectors x.
- Monotonicity: If xi ≤ yi for each i, then Mx ≤ My
It follows
- Boundedness: min x ≤ Mx ≤ max x
- Continuity:
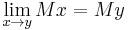
- There are means which are not differentiable. For instance, the maximum number of a tuple is considered a mean (as an extreme case of the power mean, or as a special case of a median), but is not differentiable.
- All means listed above, with the exception of most of the Generalized f-means, satisfy the presented properties.
- If f is bijective, then the generalized f-mean satisfies the fixed point property.
- If f is strictly monotonic, then the generalized f-mean satisfy also the monotony property.
- In general a generalized f-mean will miss homogeneity.
The above properties imply techniques to construct more complex means:
If C, M1, ..., Mm are weighted means and p is a positive real number, then A and B defined by
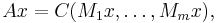
![B x = \sqrt[p]{C(x_1^p, \dots, x_n^p)} ,](/2012-wikipedia_en_all_nopic_01_2012/I/edd2370f2b8021ec0c8e01581fbe7ff2.png)
are also weighted means.
Unweighted mean
Intuitively spoken, an unweighted mean is a weighted mean with equal weights. Since our definition of weighted mean above does not expose particular weights, equal weights must be asserted by a different way. A different view on homogeneous weighting is, that the inputs can be swapped without altering the result.
Thus we define M to be an unweighted mean if it is a weighted mean and for each permutation π of inputs, the result is the same.
- Symmetry: Mx = M(πx) for all n-tuples π and permutations π on n-tuples.
Analogously to the weighted means, if C is a weighted mean and M1, ..., Mm are unweighted means and p is a positive real number, then A and B defined by
![B x = \sqrt[p]{M_1(x_1^p, \dots, x_n^p)} ,](/2012-wikipedia_en_all_nopic_01_2012/I/7be2589fcd93bf4c2c4f1df5b38c16ba.png)
are also unweighted means.
Convert unweighted mean to weighted mean
An unweighted mean can be turned into a weighted mean by repeating elements. This connection can also be used to state that a mean is the weighted version of an unweighted mean. Say you have the unweighted mean M and weight the numbers by natural numbers  . (If the numbers are rational, then multiply them with the least common denominator.) Then the corresponding weighted mean A is obtained by
. (If the numbers are rational, then multiply them with the least common denominator.) Then the corresponding weighted mean A is obtained by
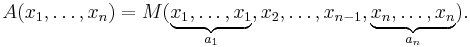
Means of tuples of different sizes
If a mean M is defined for tuples of several sizes, then one also expects that the mean of a tuple is bounded by the means of partitions. More precisely
- Given an arbitrary tuple x, which is partitioned into y1, ..., yk, then
-
- (See Convex hull.)
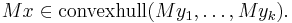
Population and sample means
The mean of a population has an expected value of μ, known as the population mean. The sample mean makes a good estimator of the population mean, as its expected value is the same as the population mean. The sample mean of a population is a random variable, not a constant, and consequently it will have its own distribution. For a random sample of n observations from a normally distributed population, the sample mean distribution is
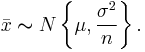
Often, since the population variance is an unknown parameter, it is estimated by the mean sum of squares, which changes the distribution of the sample mean from a normal distribution to a Student's t distribution with n − 1 degrees of freedom.
See also
- Algorithms for calculating mean and variance
- Average, same as central tendency
- Descriptive statistics
- For an independent identical distribution from the reals, the mean of a sample is an unbiased estimator for the mean of the population.
- Kurtosis
- Law of averages
- Median
- Mode (statistics)
- Spherical mean
- Summary statistics
- Weighted mean
References
External links
- Weisstein, Eric W., "Mean" from MathWorld.
- Weisstein, Eric W., "Arithmetic Mean" from MathWorld.
- Comparison between arithmetic and geometric mean of two numbers
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||